Knowledge Graph(KG)에 대하여
개요
- KG에 대해서는 개인적으로 약학/의약쪽 연구를 수행하면서 밀접히 접하게 되었다.
Continue reading
회계법인과 디컨 2
기존에 말씀드린 4개 회사들입니다. 다시한번 보지요.
Continue reading
MS-Azure 데이터 팩토리로 구축하는 ETL 파이프라인

Continue reading
개요
근 8년간 획법인에 근무한 짬밥을 기반으로 본 포스팅을 작성합니다.
Continue reading
MS-Azure 데이터 팩토리로 구축하는 ETL 파이프라인
Continue reading
MS-Azure 자격증 AZ Fundamental 900
AZ-900 자격증이란?
Continue reading
빅데이터를 지탱하는 기술 (책을 통한 스터디 2)

Continue reading
빅데이터를 지탱하는 기술 (책을 통한 스터디 1)
들어가며
Continue reading
ES - 키바나를 활용한 데이터 시각화

Continue reading
ES - 일래스틱서치 개요와 기본기능
Continue reading
글또 6기를 시작하며
난생 처음으로 글쓰는 또라이라는 모임에 가입해서.. 글을 꾸준히 강제적으로 쓸 수 있게 되어 행운이다. 특별히 전체를 운영해주시고 이끄시는 변성윤님께 감사의 말을 먼저 전달 드리고 싶다.
Continue reading
YOLO V1 - 개요
Continue reading
RPN(Region Proposal network)
Continue reading
1-stage vs. 2-stage Detector
Continue reading
1.이미지 처리 개요
Continue reading
Overview
- What is ML?? & What is Human Intelligence??
- input: Information
- Output: Inference
- ML needs lots of training data
- Rule based vs. Representation learning ?
- Pytorch
- A python package that provides two high-level features:
- Tensor computation (like numpy) with strong GPU acceleration
- Deep Neural Networks built on a tape-based autograd system
- More Pythonic (Imperative)
- Flex, Intuitive, cleaner code, easy to debug
- More Neural Networkic
- Write code as the network works
- forward/backward
Continue reading
Time Series
시계열, 타임시리즈 데이터에 분석에 대해 알아보자. 
Continue reading
Regression
Continue reading
System Trading
시스템 트레이딩의 정의
- 다양한 금융데이터를 직접 가공 분석하여 추출한 지표를 이용하여
- 이를 통한 투자 아이디어나 매매 로직을 계량화, 코드화 하여
- 과거데이터에 ‘백테스팅’ 해보고 이를 실전까지 바로 투입할 수 있는 프로세스를 하나로 시스템화
- 인간의 개입을 최소화 하는 투자 방법
Continue reading
Graph Neural Net
Grpah라는 자료구조
Continue reading
NLP - Language Modeling (LM)
언어 모델에 대해 알아봅니다.
Continue reading
```python import keras keras.version
Continue reading
FinanceDataReader Package
FinanceDataReader 라는 엄청난 패키지가 어떤분이 개발하셨는지는 몰라도 재무데이터 모으는 나같은 사람에겐 실무에 큰 도움이 되었다. 진심 감사드린다. 이 패키지를 설치하고 임포트해서 간단한 주가 시계열 분석을 진행해보고자 한다. 나도 제대로 써보는 건 처음이라.. 그래도 누군가 이 포스트를 보고 도움이 되기를 간절히 바란다. 내가 하고픈 건, 원하는 주식 또는 상장ETF의 종가 Movement를 아래 그래프처럼 시각화 해보고자 한다.
Continue reading
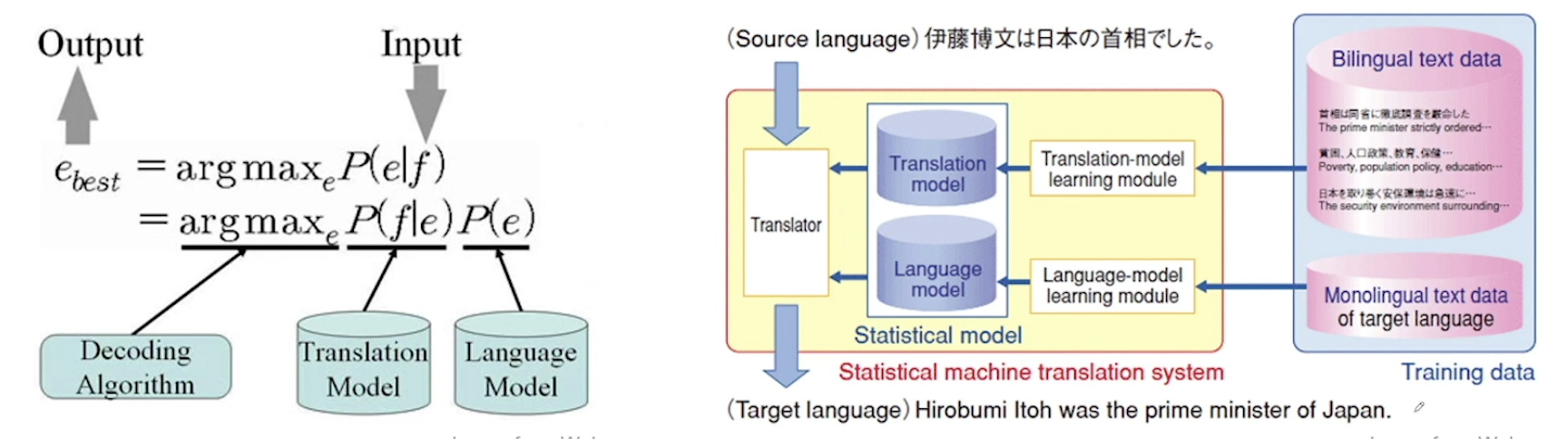
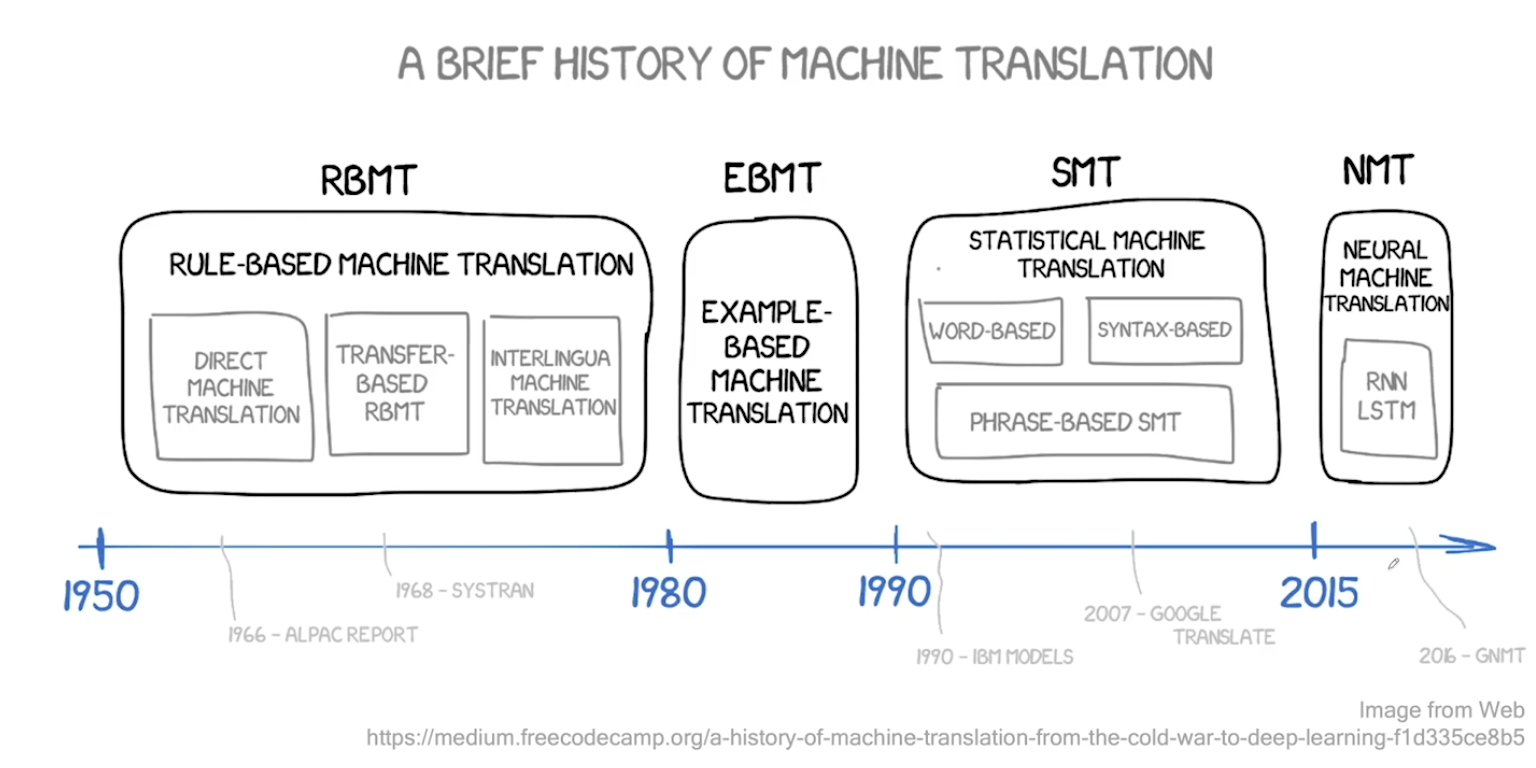
Intro to Machine Translation
- 과거 1950년대부터 시작되었음. Electronic Brain, Russian to English 에 대한 시도들이 있었다.
- Rule Based MT (RBMT) - 룰 기반이라 확장이 어렵다.
- Statistical MT (SMT) - 처음에 구글때문에 알려지게 됨. 구글번역기의 시초. 구조가 복잡하게 형성되어 있는게 단점이었음. 통계기반이기 때문에 코퍼스만 있다면 그대로 적용 가능했었다.
- 2014년에 Neural Machine Translation 관련 연구가 폭발하듯 증가 및 성공. 시퀀스 투 시퀀스의 등판!
- 현재 상용화 되어 있는 시스템은 대부분 NMT 이다.
Continue reading
Auto-regressive & Teacher Forcing
오토리그레시브한 테스크, 그리고 티처포싱 이라는 방식에 대해 알아봅니다.
Continue reading
n-gram 정리
n-gram 알고리즘에 대해 다시 정리합니다!
Continue reading
Interpolation & Back-off
- 수치 보간법이라고 한글로 불리움.. 수학과 수업에서 들어본 듯.
- 다른 LM을 linear하게 일정 비율로 섞는 것
- general domain LM + domain specific LM = general domain에서 잘 동작하는 domatin adapted LM
- 예시: 의료/법률/특허 관련 AST/MT system등이 있다.
- 추가 질문
- 그냥 domain specific corpus로 LM을 만들면 안되는지?
- 그렇게 되면 unseen word seq가 너무 많을 것 같다..
- 그냥 전체 corpus를 합쳐서 LM을 만들면 안되나요?
- Domain specific corpus의 양이 너무 적어서 반영이 안될 수도?
- Interpolation에서 ratio(lambda)를 조절하여 중요(weight)를 조절
- 명시적으로 (explicit) 섞을 수 있다.
- General domain test set, Domain specific test set 모두에서 좋은 성능을 찾는 hyper-parameter Lambda를 찾아야 한다.
- Back-off (뒤로 가면서 n을 줄여가는 것)
- 희소성에 대처하는 방법
- Markov assumption처럼 n을 점점 줄여가면 ?
- 조건부 확률에서 조건부 word seq를 줄여가면, unknown word가 없다면 언젠가는 확률을 구할 수 있다!
Continue reading
Intro to Language Modeling(LM)
- 언어모델, LM은 “문장의 확률”을 나타낸 모델
- 구체적으로는 ‘문장 자체의 출현 확률’을 예측하는 모델
- 또는 이전 단어들이 주어졌을 때 ‘다음 단어’를 예측하기 위한 모델
- 우리 머릿속에는 단어와 단어 사이의 확률이 우리도 모르게 학습되어 있다.
- 많은 문장들을 수집하여, 단어와 단어 사이의 출현 빈도를 세어 확률을 계산!
- 궁극적인 목표는 우리가 일상 생활에서 사용하는 언어의 문장 분포를 정확하게 모델링 하는 것/ 또는 잘 근사(Approximation) 하는 것
- 특정 도메인의 문장의 분포를 파악하기 위해서 해당 분야의 말뭉치 Corpus를 수집하기도 한다. (어른과 어린이의 LM이 다르고,, 의사와 일반인이 다르고.. 등등)
- 한국어 NLP는 왜 어렵나? 바로 교착어이기 때매.. 어순이 안중요. 접사에 따라 역할이 정해지기 떄문.. 단어와 단어 사이의 확률을 계산하는데 불리하게 작용하는.. 그리고 생략도 가능하기 때매 종종..
- 따라서, 확률이 퍼지는 현상이 한국말엔 존재하게 됨
- 접사를 따로 분리해주지 않으면 어휘의 수가 기하급수적으로 늘어나 희소성이 더욱 늘어난다.
- 언어모델 LM의 적용분야 (NLG Task에대해 매우 중요한 역할을 하더라..)
- 1)Speech Recognition: Acoustic Model과 결합하여, 인식된 Phone의 sequence에 대해서 좀 더 높은 확률을 갖는 sequence로 보완
- 2)번역 모델과 결합하여, 번역 된 결과 문장을 자유스럽게 만듦
- 3)OCR : 인식된 character candidate sequence에 대해서 좀 더 높은 확률을 갖는 sequence를 선택하도록 도움
- 4)Other NLG Tasks: 뉴스기사 생성, 챗봇, 검색어 자동완성 등등.
- ASR(Automatic Speech Recognition)
- x=음성, y=word sequence
| argmaxP(x | y)P(y) === AM과 LM의 확률의 곱임. |
Continue reading
Review: Statistical & Geometric Perspective for Deep Learning
Continue reading
NLP - Language Modeling (LM)
언어모델 (LM)이란 문장의 확률을 나타낸 모델
- 문장 자체의 출현 확률을 예측 하거나,
- 이전 단어들이 주어졌을 때 다음 단어를 예측하기 위한 모델
Continue reading