이미지처리 - Faster RCNN 2
in Data Science on ML/DL
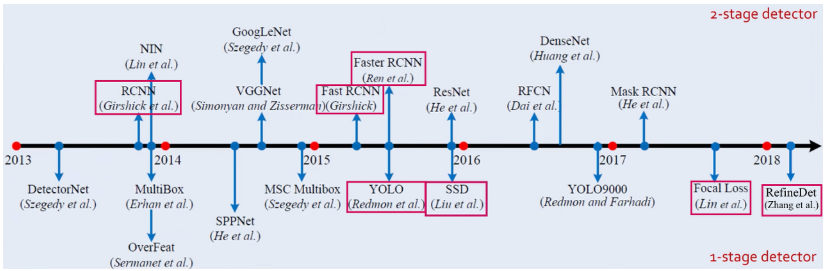
1-stage vs. 2-stage Detector
1-stage detector vs. 2-stage detector
 Source: https://blog.kakaocdn.net/dn/rd2Ho/btqBcxO6C0m/MCINIrwGAnzMjevTDOqKJ0/img.png
Source: https://blog.kakaocdn.net/dn/rd2Ho/btqBcxO6C0m/MCINIrwGAnzMjevTDOqKJ0/img.png
- RCNN 계열 : 2-STAGE (속도 느리고 정확도 좋음)
- YOLO 계열: 1-STAGE (속도 빠르고 정확도 떨어짐)
Faster RCNN
Faster R-CNN: Towards Real-Time ObjectDetection with Region Proposal Networks
후보 영역 추출을 위해 사용되는 Selective search 알고리즘은 CPU 상에서 동작
이로 인해 네트워크에서 병목현상이 발생하는 이슈
Faster R-CNN은 이러한 문제를 해결하고자 후보 영역 추출 작업을 수행하는 네트워크인 Region Proposal Network(이하 RPN)를 도입
RPN은 region proposals를 보다 정교하게 추출하기 위해 다양한 크기와 가로세로비를 가지는 bounding box인 Anchor box를 도입
Faster R-CNN 모델을 간략하게 보면 RPN과 Fast R-CNN 모델이 합쳐졌다고 볼 수 있음
RPN에서 region proposals를 추출하고 이를 Fast R-CNN 네트워크에 전달하여 객체의 class와 위치를 예측합니다.
이를 통해 모델의 전체 과정이 GPU 상에서 동작하여 병목 현상이 발생하지 않으며, end-to-end로 네트워크를 학습시키는 것이 가능
- 원본 이미지를 pre-trained된 CNN 모델에 입력하여 feature map을 획득
- feature map은 RPN에 전달되어 적절한 region proposals을 산출
- region proposals와 1) 과정에서 얻은 feature map을 통해 RoI pooling을 수행하여 고정된 크기의 feature map을 획득
- Fast R-CNN 모델에 고정된 크기의 feature map을 입력하여 Classification과 Bounding box regression을 수행
Anchor Box
Selective search를 통해 region proposal을 추출하지 않을 경우, 원본 이미지를 일정 간격의 grid로 나눠 각 grid cell을 bounding box로 간주하여 feature map에 encode하는 Dense Sampling 방식을 사용
이같은 경우 sub-sampling ratio를 기준으로 grid를 나누게 됨.
가령 원본 이미지의 크기가 800x800이며, sub-sampling ratio가 1/100이라고 할 때, CNN 모델에 입력시켜 얻은 최종 feature map의 크기는 8x8(800x1/100)가 됨.
여기서 feature map의 각 cell은 원본 이미지의 100x100만큼의 영역에 대한 정보를 함축하고 있다고 할 수 있음.
원본 이미지에서는 8x8개만큼의 bounding box가 생성된다고 볼 수 있습니다.
이 글이 도움이 되셨다면 추천 클릭을 부탁드립니다 :)
