Data Engineering - End to End Architecture
in Data Science on Engineering
End-to-End 아키텍쳐
빅데이터 처리를 위한 데이터 레이크(Data Lake)
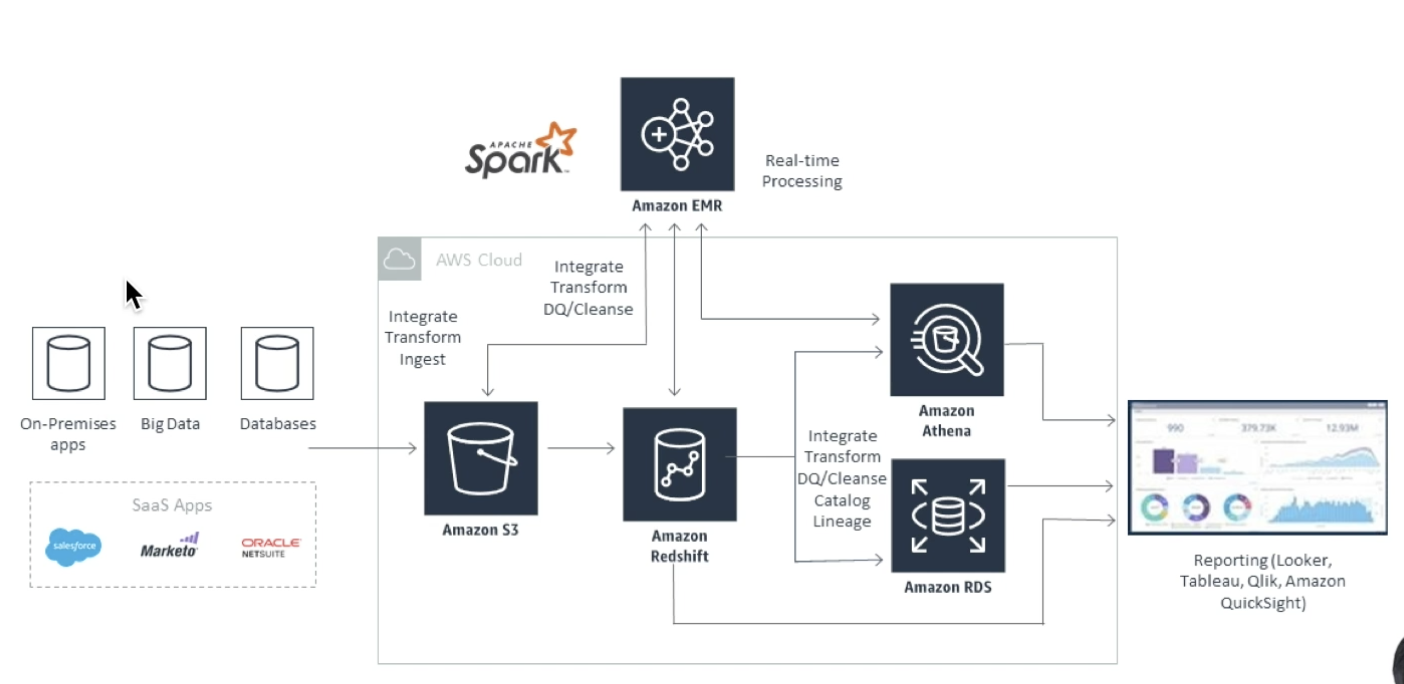
온프렘, 빅데이터, 디비 등 여러 곳에서 데이터가 몰려들어온다.
이러한 데이터를 Amazon S3에 저장된다.
Amazon EMR이라는 리얼타임 프로세싱 서버에서 스파크로 처리를 한다.
처리된 데이터가 Amazon Redshift에 넣고
Redshift로 부터 Amazon RDS 또는Presto 위에 얹어져 있는 서버리스 Amazon Athena로 전달되어져 리포팅 및 시각화 구현
넷플릭스 데이터 시스템 예시
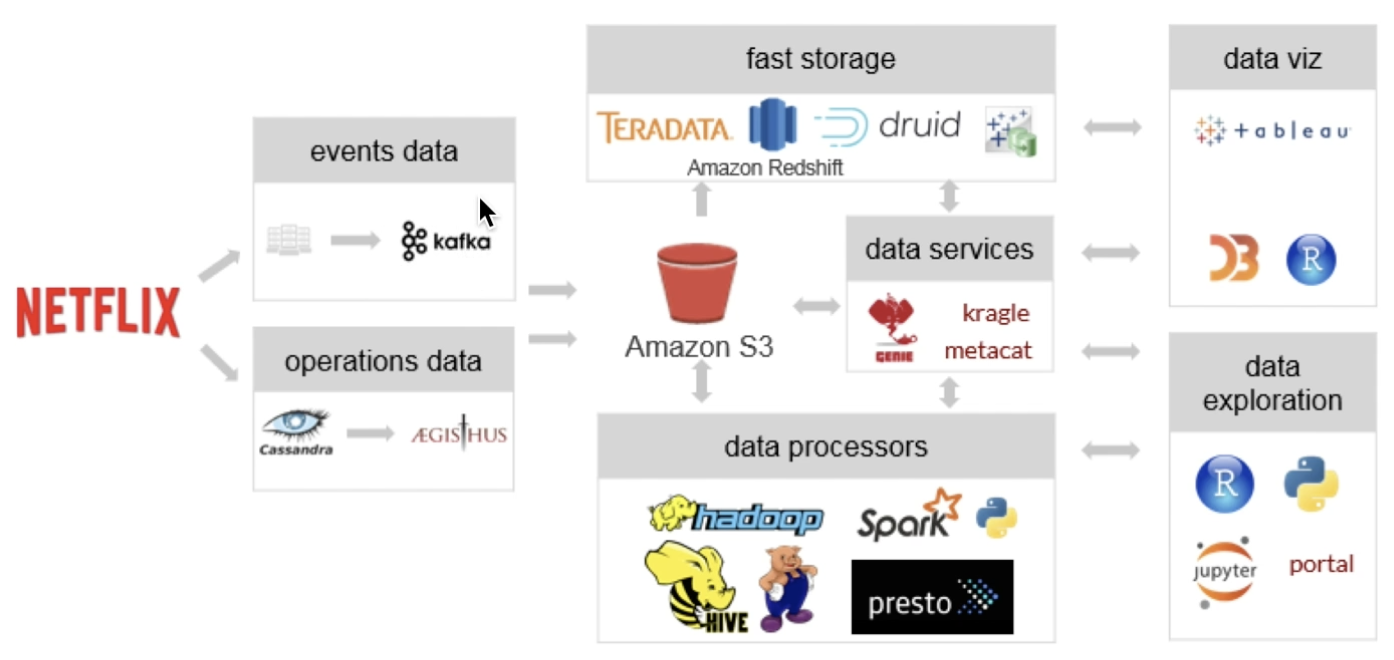
UBER 데이터 아키텍처 예시
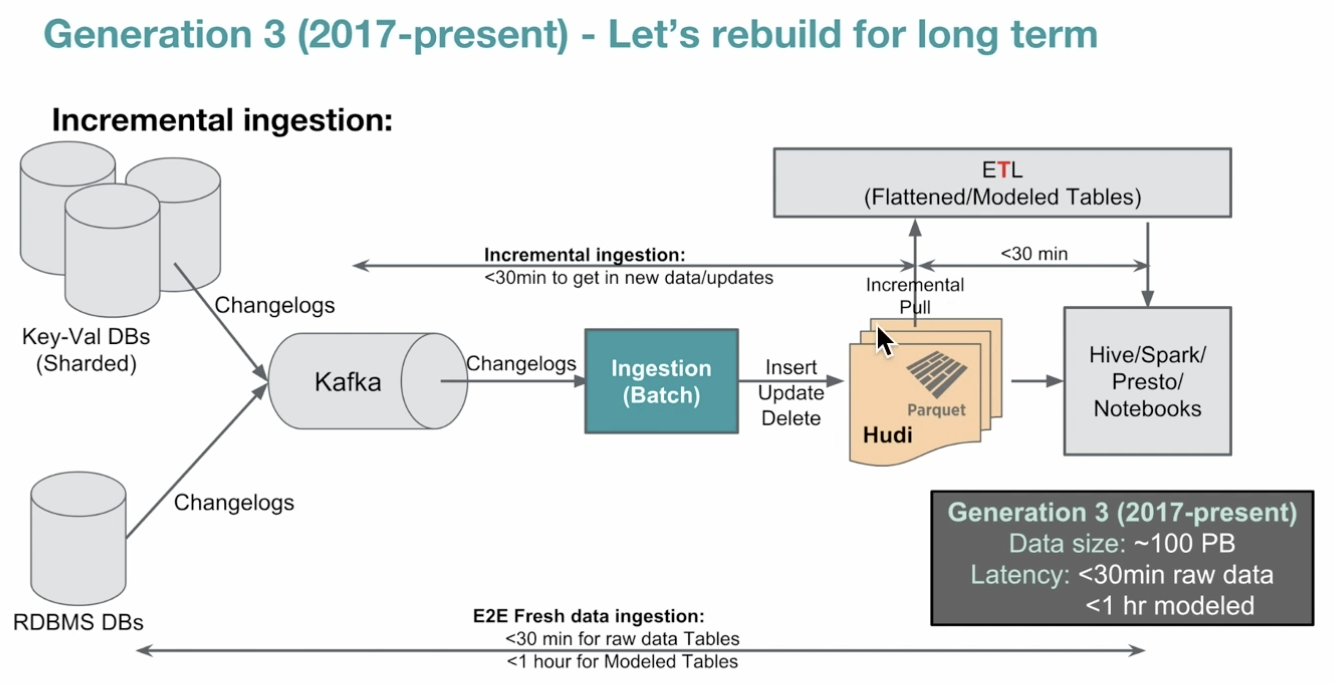
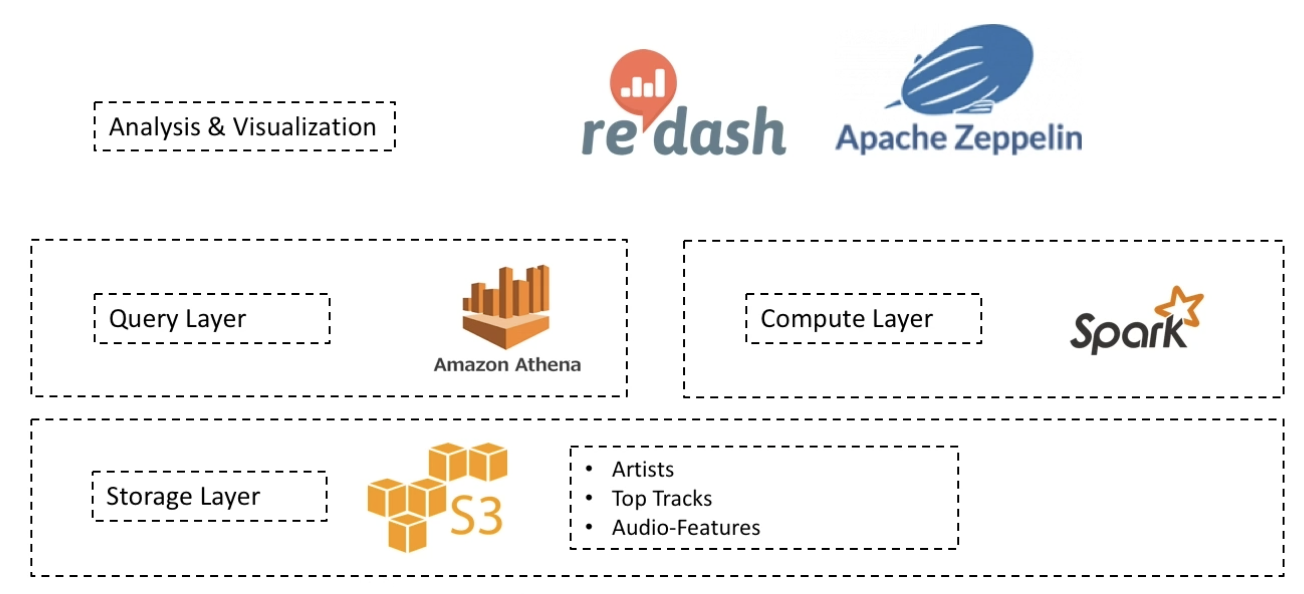
Spotify Prj - 데이터 아키텍쳐
Adhoc vs. Automated
Adhoc 분석 환경 구축은 서비스를 지속적으로 빠르게 변화시키기 위해 필수적인 요소
이니셜 데이터 삽입, 데이터 백필 등을 위해 Adhoc 데이터 프로세싱 시스템 구축 필요
Automated: 이벤트, 스케쥴 등 트리거를 통해 자동화 시스템 구축
아티스트 관련 데이터 수집 프로세스
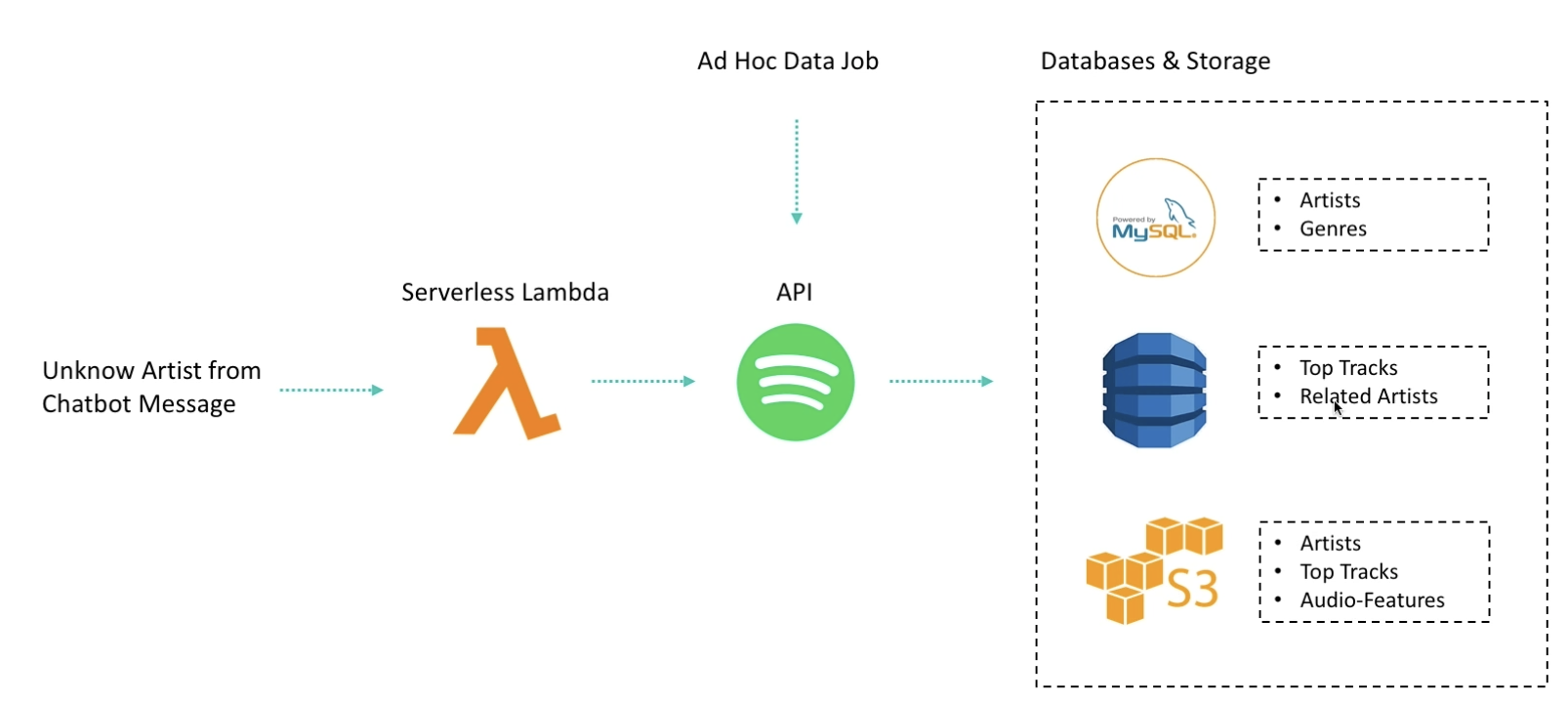
데이터 분석 환경 구축
서비스 관련 데이터 프로세스
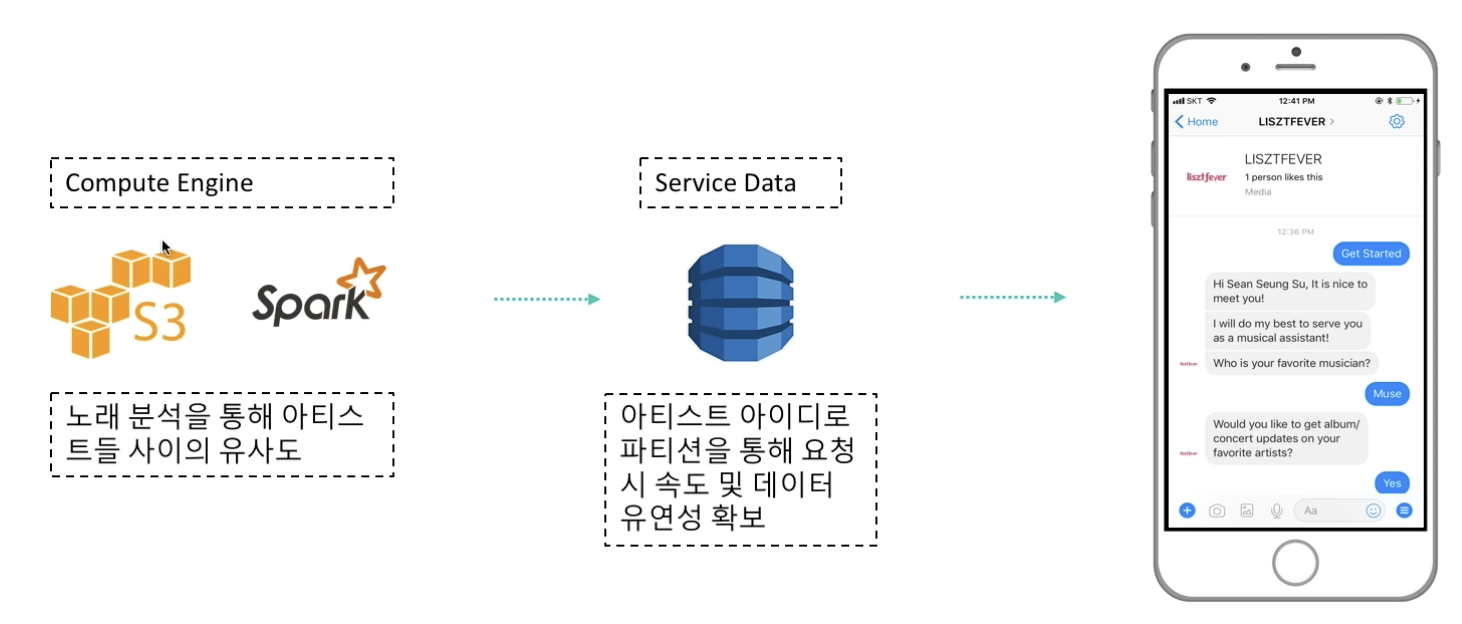
- 다이나모 DB(NoSQL)에 저장 및 바로 챗봇에 반영
- Why DynamoDB? 퍼포먼스가 좋으며, 다양한 형태로 유기적 변형 가능
이 글이 도움이 되셨다면 추천 클릭을 부탁드립니다 :)
