자연어처리 - 언어모델링(LM)
in Data Science on ML/DL
Intro to Machine Translation
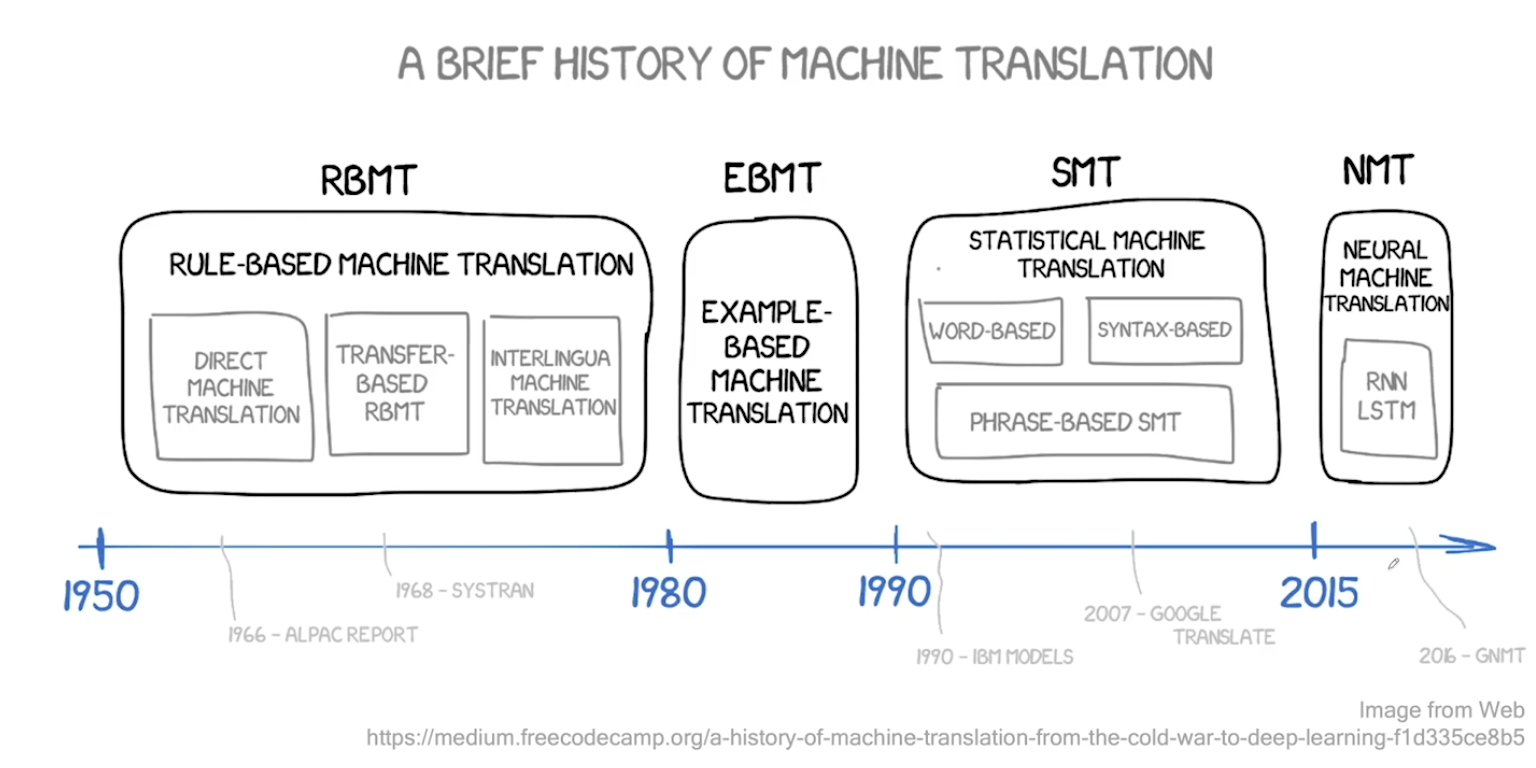
- 과거 1950년대부터 시작되었음. Electronic Brain, Russian to English 에 대한 시도들이 있었다.
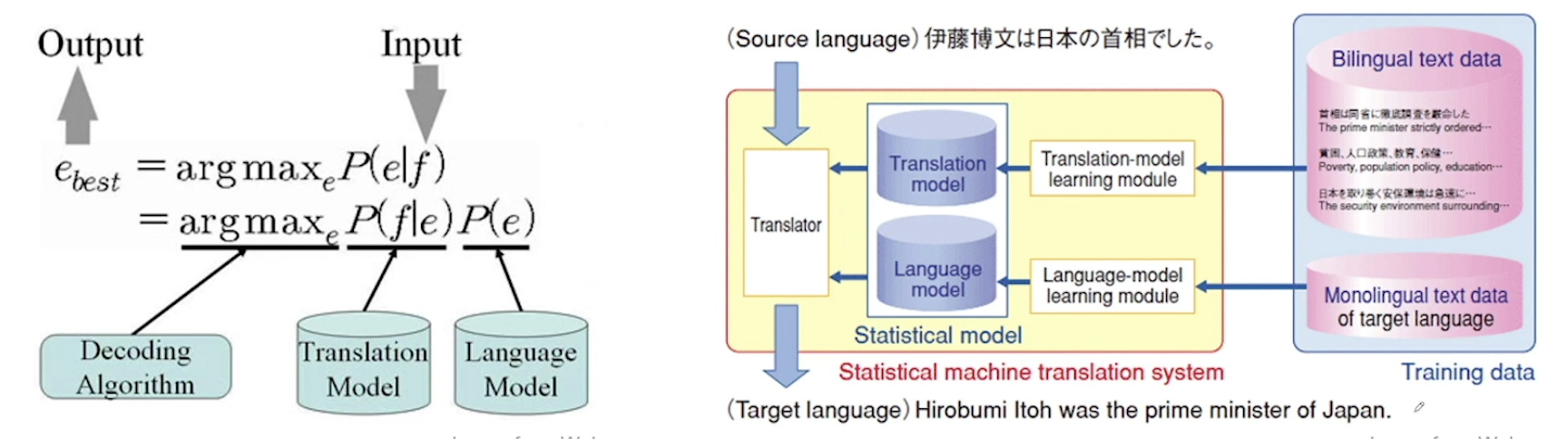
- Rule Based MT (RBMT) - 룰 기반이라 확장이 어렵다.
- Statistical MT (SMT) - 처음에 구글때문에 알려지게 됨. 구글번역기의 시초. 구조가 복잡하게 형성되어 있는게 단점이었음. 통계기반이기 때문에 코퍼스만 있다면 그대로 적용 가능했었다.
- 2014년에 Neural Machine Translation 관련 연구가 폭발하듯 증가 및 성공. 시퀀스 투 시퀀스의 등판!
- 현재 상용화 되어 있는 시스템은 대부분 NMT 이다.
- 왜 딥러닝 자연어처리가 기존 자연어처리를 압도할 수 있을까?
- End-to-end 모델이다.
- SMT 방식은 여러 sub-module이 진행될 수록 error가 가중된다.
- Generalization을 잘한다.
- Discrete한 단어를 continuous 한 값으로 변환하여 계산 (워드 임베딩, 컨텍스트 임베딩)
- LSTM과 Attention의 적용
- Sequence의 길이에 구애받지 않고 구동
- End-to-end 모델이다.
Sequence to Sequence
- 다음 3가지로 구성되어 있다.
- Encoder
- Decoder
- Generator
- Given dataset, find parameter that maximize likelihood and minize loss function by updating parameter with gradient descent
- 활용영역
- NMT
- Chatbot
- Summarization
- Other NLP Task
- 음성인식 ASR
- Image Captioning
Seq-to-Seq : Encoder
- Encoder의 역할은?
- 문장을 Vector화 하는 것
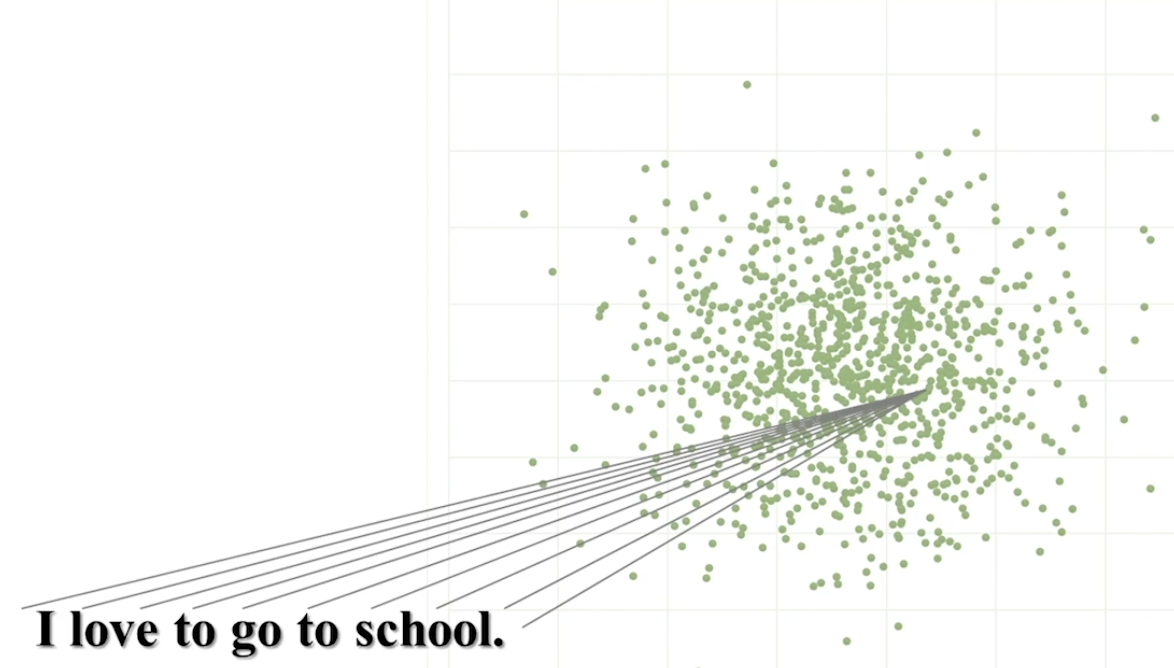
- 수식으로 표현해보면?
- Given dataset, get hidden states of encoder.

- 요약
- Encoder는 source문장을 압축한 context vector를 decoder에게 넘겨주는 역할을 한다.
- Encoder는 train/test시에 항상 문장 전체를 받는다.
- Encoder 자체만 놓고 보면 non-Autoregressive task이기 떄문
- 따라서 bi-directional RNN사용이 가능
이 글이 도움이 되셨다면 추천 클릭을 부탁드립니다 :)
