자연어처리 - Auto-regressive & Teacher Forcing
in Data Science on ML/DL
Auto-regressive & Teacher Forcing
오토리그레시브한 테스크, 그리고 티처포싱 이라는 방식에 대해 알아봅니다.
RNN의 구분?
또 다른 구분?
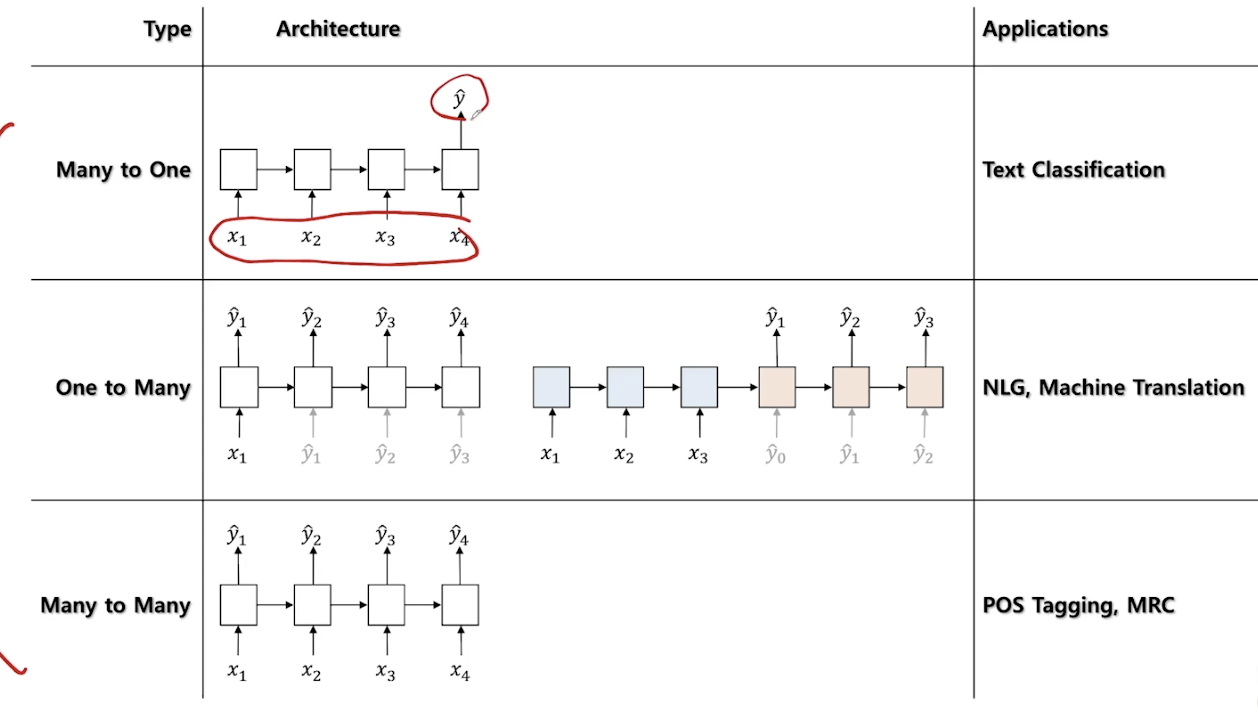
- 1)Non-autoregressive(Non-generative)
- 현재 상태가 앞/뒤 상태를 통해 정해지는 경우
- e.g. Part of Speech Tagging (POS Tagging), Text Classification
- Bidirectional RNN 싸용 권장
- 현재 상태가 앞/뒤 상태를 통해 정해지는 경우
- 2)Autoregressive(Generative)
- 현재 상태가 과거 상태에 의존하여 정해지는 경우
- e.g. NLG, Machine Translation
- One-to-Many 케이스에 해당
- Bidirectional RNN 사용 불가
- 현재 상태가 과거 상태에 의존하여 정해지는 경우
- 1)Non-autoregressive(Non-generative)
Auto-regressive
- 과거 자신의상태를 참조하여 현재 자신의 상태를 업데이트 하는 것
Teacher-Forcing
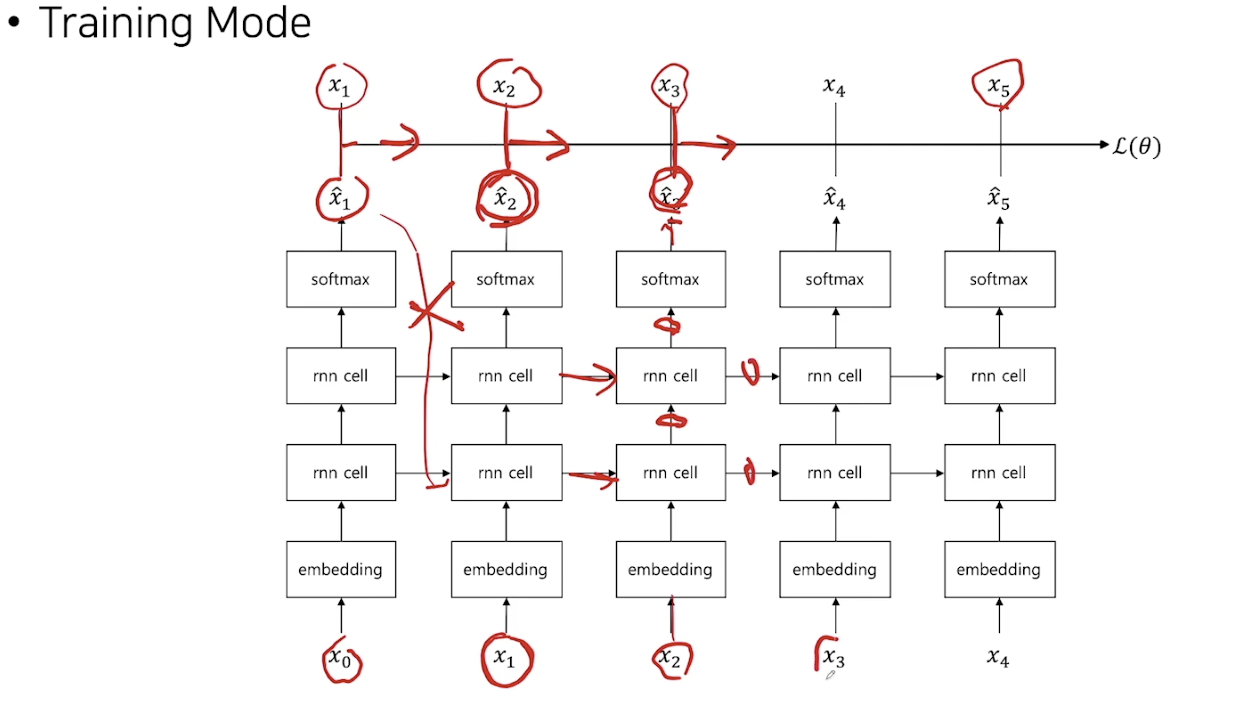
- MLE의 수식상, 정답 x t-1을 RNN의 입력으로 넣어줘야 함.. 나름 학습과 인퍼런스도 잘 되긴하는데..
고통의 시작: NLG is Auto-regressive Task
- Auto-regressive task에서는 보통 이전 타임스텝의 모델을 출력을 다음 타임스텝의 입력으로 넣어줌
- 이전 타임스텝의 출력에 따라 현재 모델의 state가 바뀌게 될 것
- 하지만 적절한 학습을 위해서는 학습시에는 이전 타임스텝의 출력값이 아닌, 실제 정답을 넣어 줌
- 따라서, 학습과 추론을 위한 방법이 다르게 되어…. 여러가지 문제가 발생한다.
- 학습을 위한 코드와 추론을 위한 코드를 따로 짜야한다..!!! 헉..
- 학습과 추론 방법의 discrepancy가 발생하여 성능이 저하될 수 있더라… 정말 고통의 시작.. 일차적으로 성능은 잘 나오긴하니까.. 크게 걱정은 말자. 하지만 더 개선의 여지가 있다는 것을 기억.
- Auto-regressive task에서는 보통 이전 타임스텝의 모델을 출력을 다음 타임스텝의 입력으로 넣어줌
LM 마무리
Language Model이란?
- 실제 우리가 사용하는 또는 타깃 도메인 언어의 분포를 확률 모델로 모델링 한 것
- 체인룰에 의해
- 실제 우리가 사용하는 또는 타깃 도메인 언어의 분포를 확률 모델로 모델링 한 것
Perplexity (PPL)
- 매 타임스텝 마다 모델이 동등하게 헷갈리고 있는 평균 단어의 수. 따라서 헷갈리는 단어가 적을수록 좋은것
- 문장의 확률의 역수에 단어 수만큼 기하 평균을 취한 것. 따라서 문장의 likelihood가 높을수록 좋은 것
- Cross Entropy에 Exponential을 취한 것
- Ground Truth 분포와 모델의 분포가 비슷할수록 좋은 것
n-gram and Neural Net LM
- n-gram의 경우 단어를 discrete symbol로 인식. 카운트 기반이며 학습 코퍼스에 word sequence가 존재해야만 확률 값을 추정가능
- 쉽고 직관적인 구현이 가능한다. 선 카운팅 후 추론 가능하고 scalable 하다.
- NNLM의 경우 단어를 continuous vector로 변환시킴
- Unseen word sequence에 대처가 가능하고 generalization에 강점을 가지고 있다.
- 비싸고 느린 연산 추론 과정.. Generatino task에 굉장히 강함.
이 글이 도움이 되셨다면 추천 클릭을 부탁드립니다 :)
